In the previous post, we saw how ASCII evolved and how useful it was for communication among different devices. With ASCII, the same decimal numbers 0-127 were mapped to the same printable characters and control codes, across all computers and peripherals, creating uniformity.

The Problem
ASCII was powerful but it was limited to English. It would have worked, If Britain was the only colonial power in the world.
Unfortunately, western greed was prevalent in early modern history. Many other European countries like France, Spain, Portugal, Netherland, Germany, and a few more, claimed many other parts of the world as colonies. This led to having, French, Spanish, Portuguese, and a few more European languages as the lingua franca in a large part of the world.
On top of it, there were some countries like China, Japan, Iran, Russia & few more, which were either not colonized or not completely influenced by the west, and were still using their languages, like Mandarin, Japanese, Arabic & Slavic languages, etc.
So, after inviting the whole world into the computer party, the situation came where ASCII was not enough to communicate in all spoken languages.
Earlier solutions
ASCII Variants
When computers spread into the world, standardization institutions of various regions or countries created their own variations of 7-bit ASCII to support their non-English languages.
For example, the currency symbol. The only available currency character in Standard-ASCII is $ (36). The dollar was the world’s currency, so the symbol was needed everywhere. But other regions had their currency symbols too. So regions started trading lesser-used characters for their currency symbol. The UK replaced “#” with “£”, Japan replaced “\” with “¥”, and Korea “\” with “₩”along with a few other changes, and the story went on.
On top of it, various private corporations also created their version of 7-bit ASCII to support their devices.
Remedying the pro-English-language bias, created compatibility problems because we were still dealing with a 7-bit character set, and everyone was replacing lesser-used characters, based on their region or use case.
A better opportunity
Birth of Extended-ASCII
In the 1970s, computers & peripherals got standardized to use 8-bit-bytes. Now each byte could represent an 8-digit binary number, ranging from decimal number 0 to 255. As each number can be mapped to one character, this allowed computers to handle text that uses 256-character sets.
ASCII was using only 7 bits, equivalent to decimal numbers 0 to 127, the remaining 127 slots from 128 to 255 become available for mapping to new characters.
So unlike the earlier solutions, now institutions & corporations did not have to replace existing mapping from ASCII. reserving the existing character set, everyone added their characters for the remaining 127 available spaces. This was called Extended ASCII.
NOTE: Some regions even completely replaced all characters in their character sets. As CCCII for the Chinese language character set, developed in Taiwan. Few Japanese Characters like JIS X 0201
Still a chaos
Too many versions
This opened the wrong door. Each region started coming up with its extended character set to fit the remaining 127 slots from 128–to 255. This resulted in many different Extended-ASCII character sets.
Extended ASCII couldn’t solve interoperability or compatibility problems because it became challenging to keep track of varients, there were simply too many Extended-ASCII and no limitation in creating new ones.
Curbing the chaos
ISO 8859 N— Extended ASCII
Eventually in the 1980s, International Standardization Organization (ISO) stepped in and did what it always does. It created a few standard eight-bit ASCII extensions for non-English languages, called ISO 8859-N.
Locations 128 to 159 are mapped to the control characters in all ISO-8859. The remaining 96 characters are different in different ISO 8859-N versions.
The first one of the bunch is ISO-8859–1 shown below. It contained sufficient characters for most Western European languages.
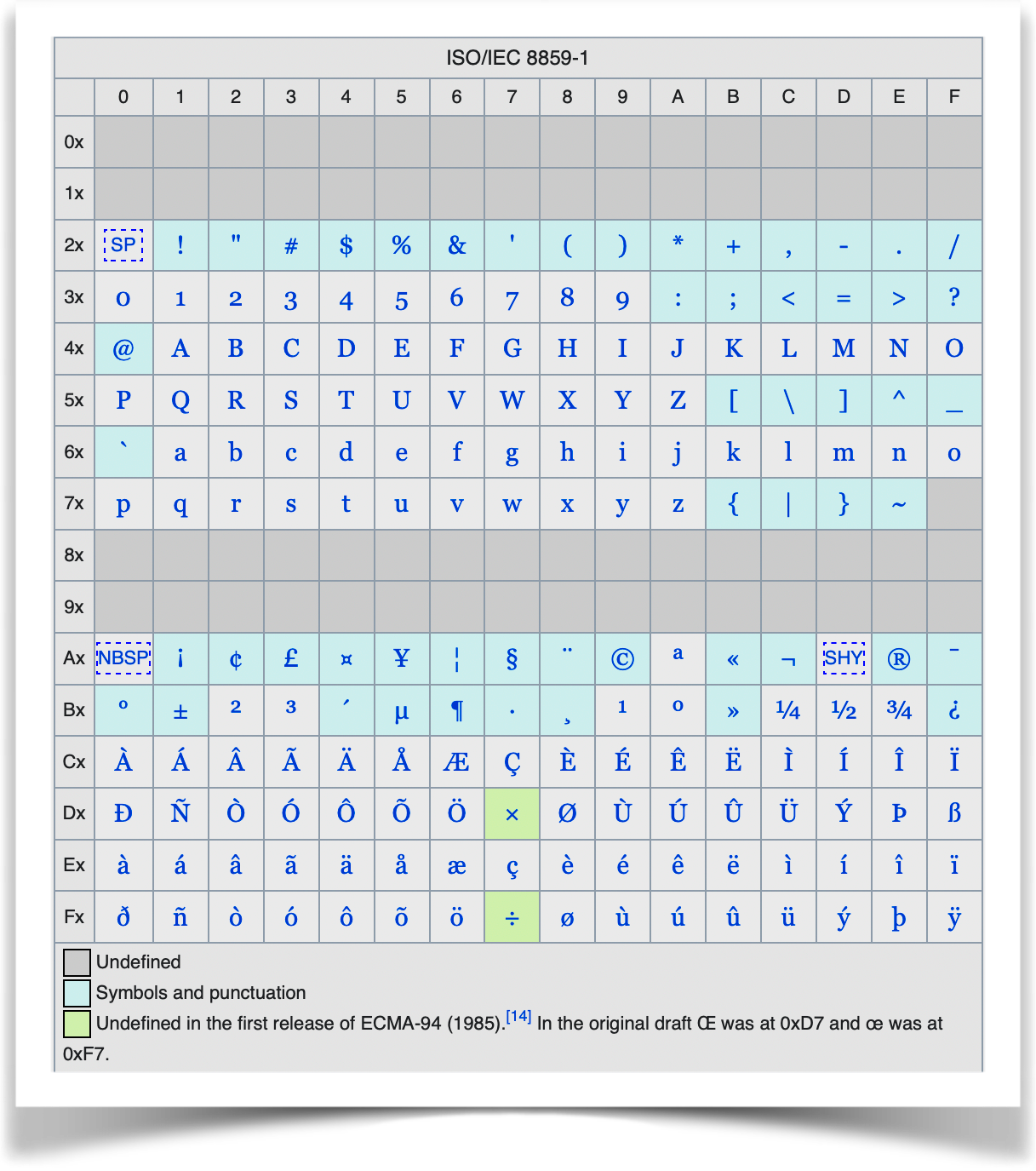
Over the course of the next 12 years, ISO tried to add all known languages and created Character sets. For example
ISO-8859–2for Central European languages,ISO-8859–3for Southern European languagesISO-8859–4for North European languages,ISO 8859–5for Cyrillic languages,ISO-8859–6for Arabic- And so on until
ISO-8859–16
Beginning of the end
Rich languages & End of ISO 8859-N
ISO 8859-N maps only 96 positions from 160 to 265. Many languages in the world have more symbols. On top of it, few ideographic, monosyllabic East Asian languages require many thousand symbols. like Mandarin, Cantonese, Japanese and Vietnamese.
So even after agreeing on the compromise of switching between 16 different predefined ISO-8859-N character sets, we were still unable to cover all major languages under the ISO standards scheme.
Due to this, a better system for character sets was created (Mentioned below paragraph). Some of the ongoing character-set development (likeISO-8859–12Devnagiri) was abandoned and started in this new system.
Birth of an ultimate solutions
Then came an invention from a company, that has a long history of inventions to help shape the course of humanity. The one & only Xerox PARC. This time invention was UNICODE. More on it in the next post.
This was all about how character sets evolved from English-speaking America to another developing world. In the next post, we will discuss UNICODE, the ultimate solution for the character set.
Comments